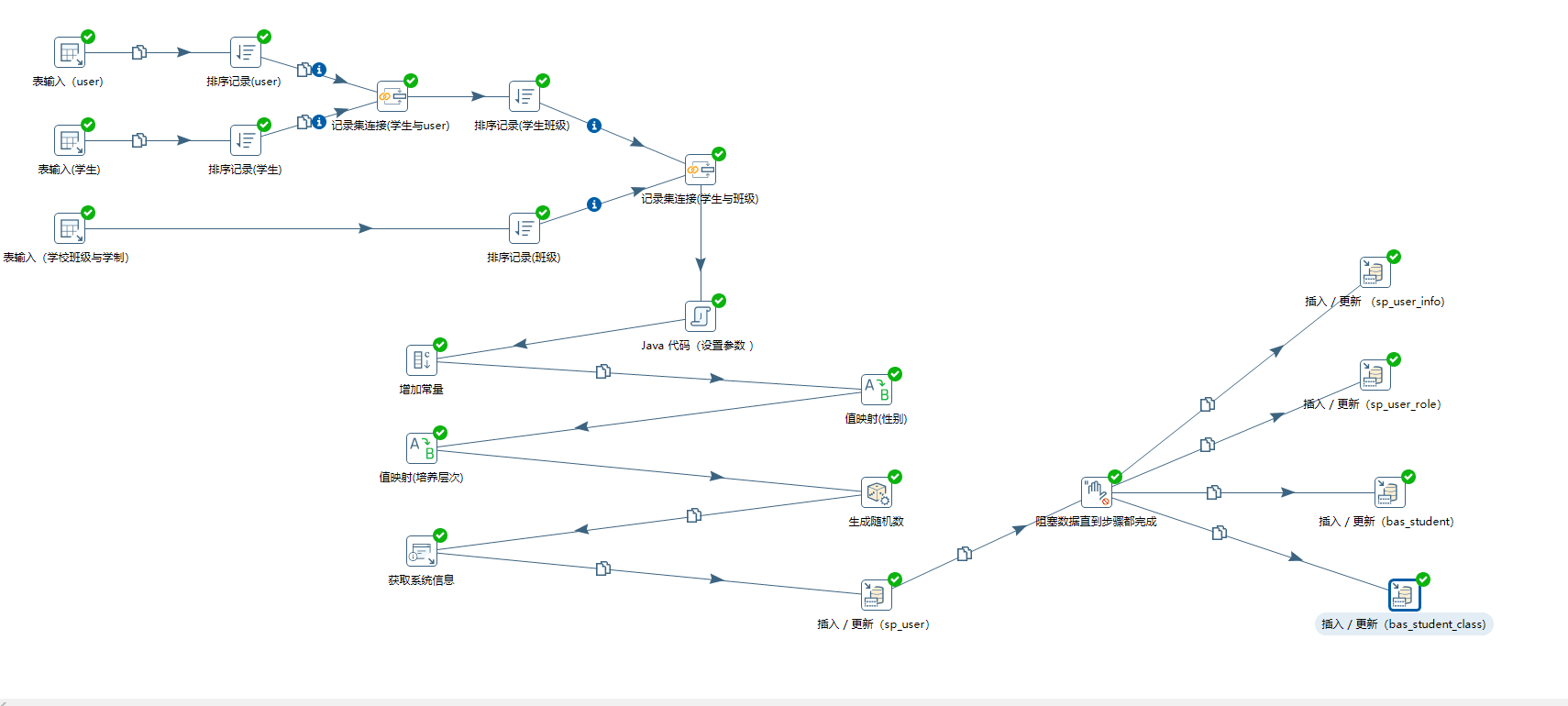
学生数据处理
学生数据的处理需要根据实际的业务来处理,这里只是根据个人的业务,项目开发中还得具体情况具体分析。
1、多输入源、排序、记录连接:
学生数据处理需要从多个数据源中获取输入源,将这些数据源的数据通过 排序 —> 记录连接(相当于sql 中的多表join 查询) 合并数据。
此步骤需要连接三个数据库获取输入的数据,主要就是配置 表输入 —> 排序记录 —> 记录集连接 这三步,你还可以根据业务添加分组等其他组件。
2、Java代码设置参数值:
此组件可以根据你的需求编写相关的 java代码,如果内置的一些方法不能满足你的业务需求,可以将你的相关jar放在 ${KETTLE_HOme}/lib 目录中,然后重启ektte工具,就可以在 此组件中使用自定义的java类。
此组件主要是根据需求重写 processRow 这个方法,并需要导入 相关的包,如下:生成用户密码、设置用户拼音、设置生日转换为日期、生成用户UUID等。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
| import com.sjq.core.utils.DigestUtils;
import com.sjq.core.utils.PinyinUtils;
import com.sjq.core.utils.DateUtils;
import java.sql.Timestamp;
import org.apache.commons.lang3.StringUtils;
import java.util.UUID;
public boolean processRow(StepMetaInterface smi, StepDataInterface sdi) throws KettleException {
Object[] r = getRow();
if (r == null) {
setOutputDone();
return false;
}
String passWord = get(Fields.In, "password").getString(r);
if(StringUtils.isEmpty(passWord)){
String stuNo = get(Fields.In, "学号").getString(r);
passWord = DigestUtils.encryptPassword(stuNo);
}
get(Fields.Out, "password").setValue(r, passWord);
String stuName = get(Fields.In, "姓名").getString(r);
get(Fields.Out, "spellName").setValue(r, PinyinUtils.converterToFirstSpell(stuName));
String endDate = get(Fields.In, "毕业时间").getString(r);
get(Fields.Out, "毕业时间").setValue(r, new Timestamp(DateUtils.parseDate(endDate).getTime()));
String brithDay = get(Fields.In, "出生日期").getString(r);
if(StringUtils.isNotEmpty(brithDay)){
get(Fields.Out, "出生日期").setValue(r, new Timestamp(DateUtils.parseDate(brithDay).getTime()));
}
String userId = get(Fields.In, "user_id").getString(r);
if(StringUtils.isEmpty(userId)){
userId = UUID.randomUUID().toString();
}
get(Fields.Out, "user_id").setValue(r, userId);
String userInfoId = get(Fields.In, "user_info_id").getString(r);
if(StringUtils.isEmpty(userInfoId)){
userInfoId = UUID.randomUUID().toString();
}
get(Fields.Out, "user_info_id").setValue(r, userInfoId);
putRow(data.outputRowMeta, r);
return true;
}
|
3、增加常量:
定义你需要常量数据。可见第二节相关内容。
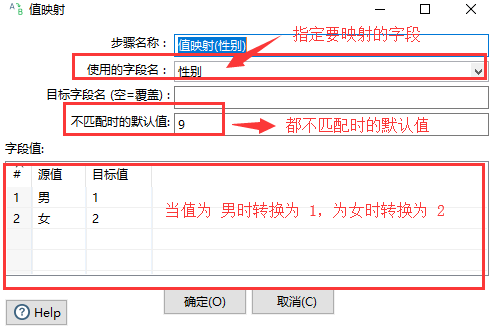
4、值映射:
可以将值映射成你想要的值。如性别 为 男的映射为 1,为女的映射为 2.
5、生成随机数:
定义你需要常量数据。可见第二节相关内容。
6、获取系统信息:
定义获取系统信息,可见第二节相关内容。
7、插入/更新 sp_user表
以上几步都配置成功后,在 sp_user 表中所有字段都能在流中找到,定义输出的表、执行插入与更新的条件、流字段与输出表字段的映射关系。即可插入或更新此表。
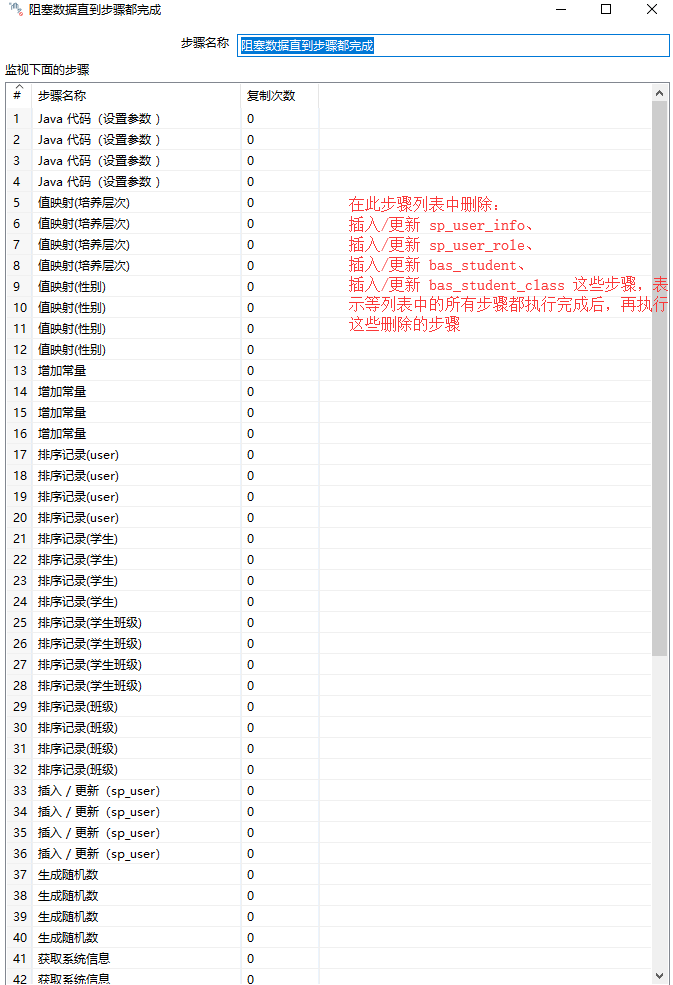
8、阻塞数据直到步骤都完成:
添加此步骤的目的是其它表(这里指的是 sp_user_info、sp_user_role、bas_student、bas_student_class 这四张表)中在插入数据时,与上一步中的 sp_user表中添加了主外键关联,因此,如果sp_user表中没有用户信息,其它表中在插入数据时就会抛出主键外错误,这也证实了,以上你所画出的流程并不是从头到尾按步执行的,这应该是该工具内部优化性能的一种机制。为了保证sp_user表中的数据插入完后,再执行其它表中数据的插入或更新,此组件就可以实现这样的功能。
9、插入/更新 其它表:
定义输出的表、执行插入与更新的条件、流字段与输出表字段的映射关系。
10、执行:
定义好上面的步骤后,按第二节的执行步骤方式执行。
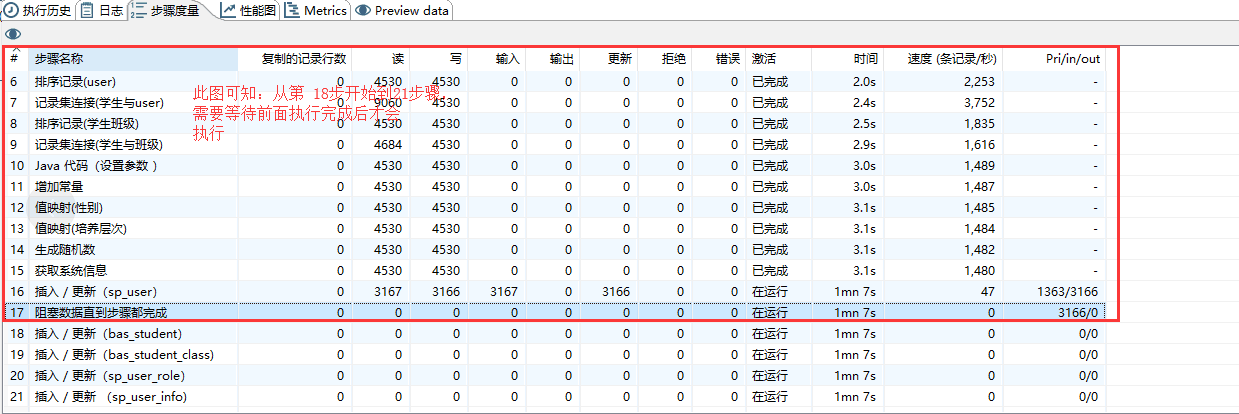
11、最终流程与日志截图 :